
KICKY AI
Local AI powered shot analyzer

Building KICKY AI a local, zero-label football shot analyzer
How I turned my own Saturday-football YouTube footage into a system that tells you: was it a goal, who scored, which foot, how hard and how to improve running on local, open models.
⚽🌎 It’s World Cup 2026. The BBC just launched a 3D immersive experience for it: switch camera angles, follow any player, see bird’s-eye tactics, all rebuilt live from multi-camera skeletal tracking on broadcast matches (BBC Sport). It’s stunning. It’s also built for the pros, on broadcast-quality feeds, with a stadium full of cameras.
But most of us play football on a Sunday pitch with one phone on a tripod. So I asked the smaller question: what about the rest of us? This is my World Cup build, a personal football analyst that runs on my own footage, fully local.
📺 I record my football journey and these builds on YouTube youtube.com/@dcrey7.
A love letter to tracking (and its trade-offs)
Object tracking is one of the most beautiful problems in computer vision. Give a model a video and ask it to follow a thing through space and time players, a ball, a goal and suddenly you can understand a game instead of just watching it. The last two years have been wild: text- promptable segmentation, grounding VLMs, real-time DETRs. The state of the art is closer than ever to a true real-time segmentation system.
But “closer than ever” is not “there yet” and the gap is a trade-off between time and quality. You can have fast or clean; getting both, on your footage, is still hard. For my use case there is a lot of cleaning up to do smoothing noisy detections, rejecting teleporting balls, recovering frames the segmenter missed so World Cup Heros is not real-time; it’s post-processed. That’s an honest design choice, not a bug.
And sports tracking specifically has some of the nastiest challenges in the field. The three biggest, in my experience:
The use case what counts as a “goal,” a “shot,” a “possession” is domain logic no model gives you for free.
Perspective one fixed, far, monocular camera means no depth and lots of foreshortening.
Ball detection a small, fast, low-contrast object is the single hardest thing to track.
This whole project is the story of fighting those three.
🙏 Huge thanks to Roboflow and Piotr Skalski (SkalskiP). His sports-CV videos and open notebooks football AI, basketball jump-shot detection, fine-tuning RF-DETR, segmenting video with SAM gave me the ideas and the scaffolding to build this. Several of those notebooks are literally in
notebooks/refernce/of this repo.
How this project started
1 · Understanding the football use case
I didn’t start from a model I started from my own data. I play football in Paris most Saturdays, and I record my football journey on YouTube. One of those videos was a shooting practice with my friend Adam Hakeem a pro player from Singapore 🐐: two of us, one goal, one phone on a tripod behind the pitch.
That defined the use case precisely: a personal football AI that, on our amateur footage, can detect our shots, understand our poses, and help coach us and crucially, one that runs completely locally on open models I own, not a cloud API. (More on why local matters to me at the end.)
2 · The data problem
Here’s the thing about “football AI”: almost all of it is built on broadcast-quality footage 4K, multi-camera, perfect angles and even then the public datasets are small. Amateur, single-camera footage is a different, harder world, and there’s very little of it.
But I’ve been recording my games for a while, so I was lucky: I had the content. I shot the session on an iPhone 15 Pro. The catch and it matters a lot downstream is that after uploading and pulling the video back from YouTube, I only get a re-encoded 1080p / 30 fps version. So the effective input is far from the original sensor quality: compressed, 30 fps, 1080p. Every limitation below traces back to that.
3 · Ball detection the hardest part
If there’s one villain in this project, it’s the ball. After a lot of trials multiple SAM variants and LocateAnything models the conclusion is blunt: the ball is brutally hard to capture in every frame. It’s:
small (often 3–4 pixels at this camera distance),
fast (so at 30 fps it smears across frames),
lit inconsistently (sun, shadow, the players’ own shadow across the pitch),
and prone to blending into the background (white-ish ball on bright grass/concrete).
And it’s not just a “use a better model” problem. Even after training on ball datasets it stays hard, for two reasons rooted in §2:
Resolution isn’t good enough a 3–4 px ball simply doesn’t carry enough signal.
Low fps gives blurry balls at 30 fps a struck ball becomes a motion-blur streak that doesn’t look like a ball to a detector.
The data backs this up. I logged every clip where SAM3 returned zero ball detections (out/noball_clips.json) it’s a real chunk of the set, including several test clips. On one test clip, spf_008, SAM3 found the ball in 0 of 117 frames. That’s the problem in one number.
The annotation tools (because someone has to label)
To even measure any of this I needed ground truth, and I wasn’t going to hand-draw thousands of boxes. So I built three tiny browser annotation tools (in notebooks/) pair-programmed with OpenAI’s Codex CLI, which was great at turning “spin up a range-streaming video server with a keyboard-driven labelling page” into working single-cell tools without me yak-shaving the plumbing. Each spins up a local HTTP server (with range-streamed video so you can scrub a big file) and serves a keyboard-driven page. Frame-navigable, persisted to JSON, no SaaS.
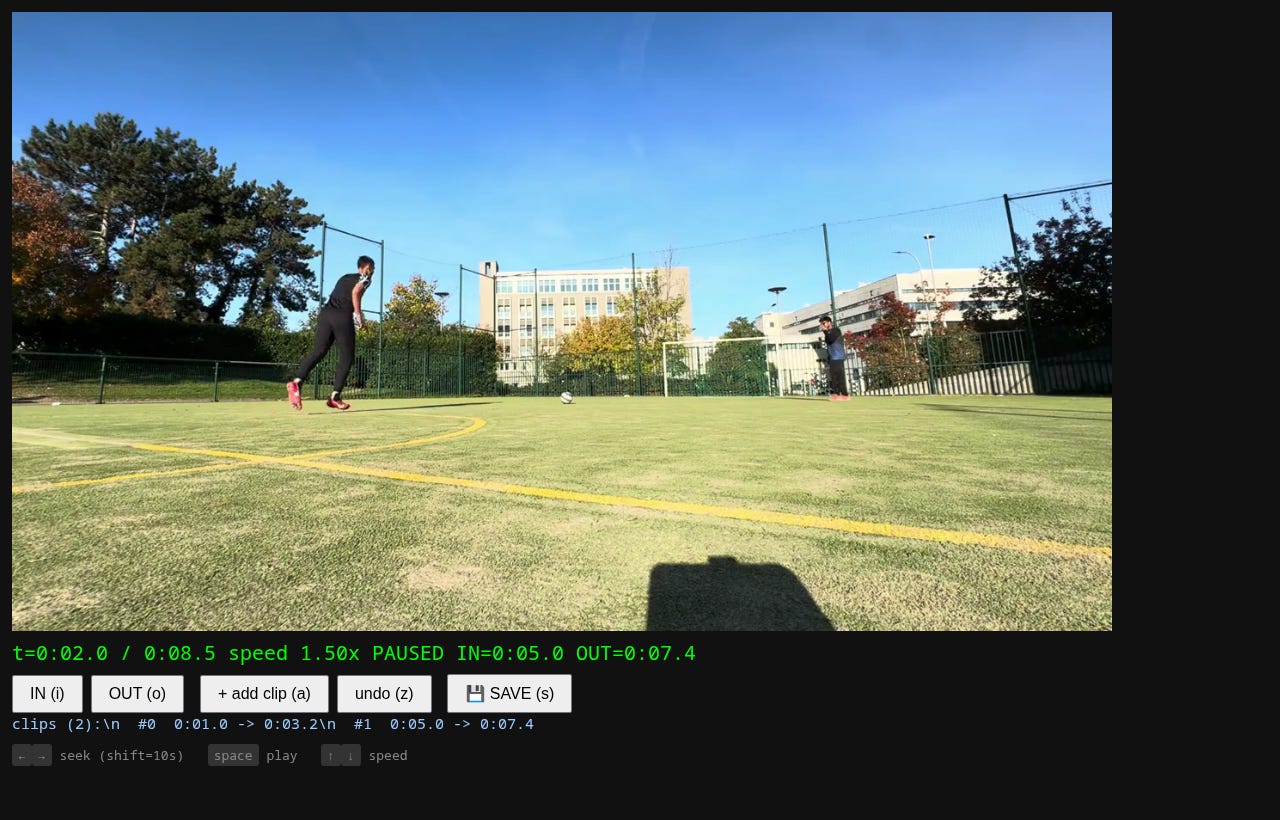
Video clipper scrub the full match, mark IN/OUT, stack cut points, export the 72 shot clips:
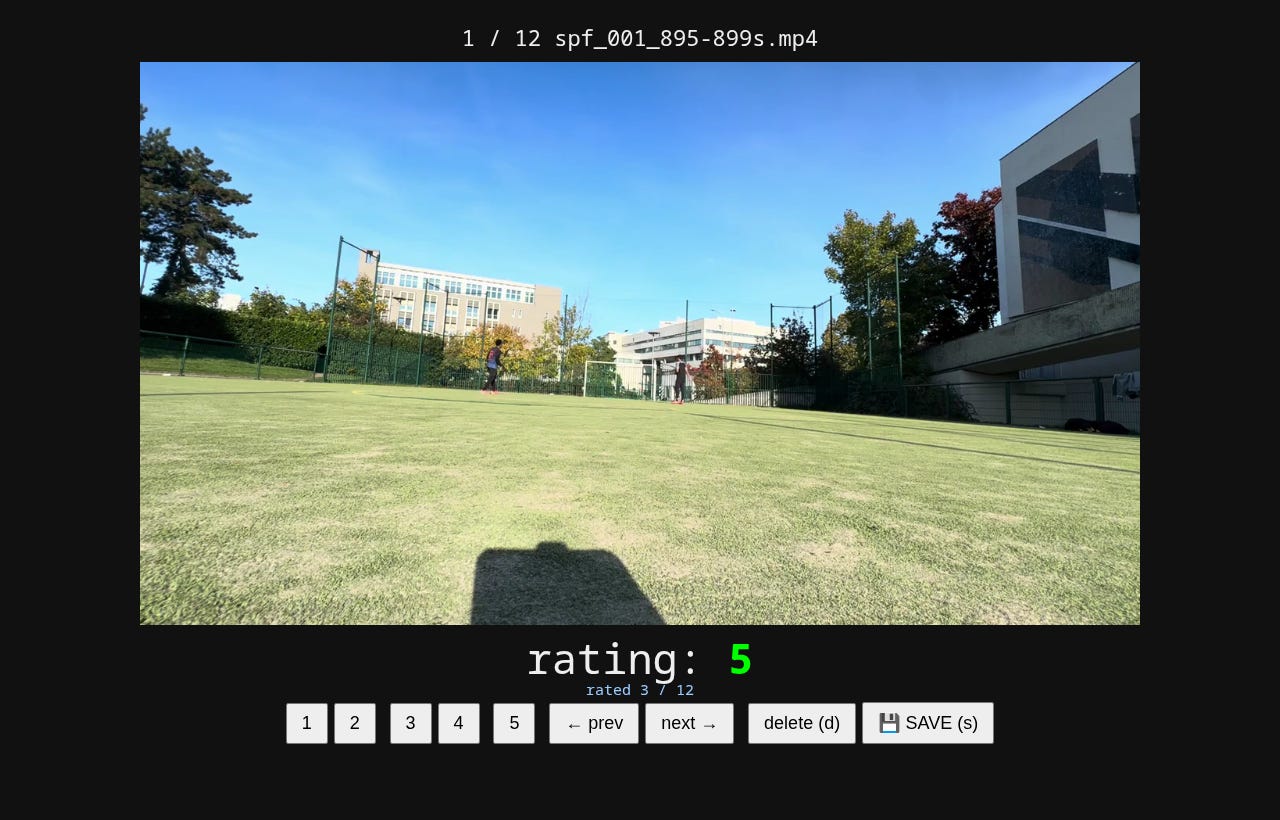
Clip rater triage each clip 5→1 stars so I work the good ones first:
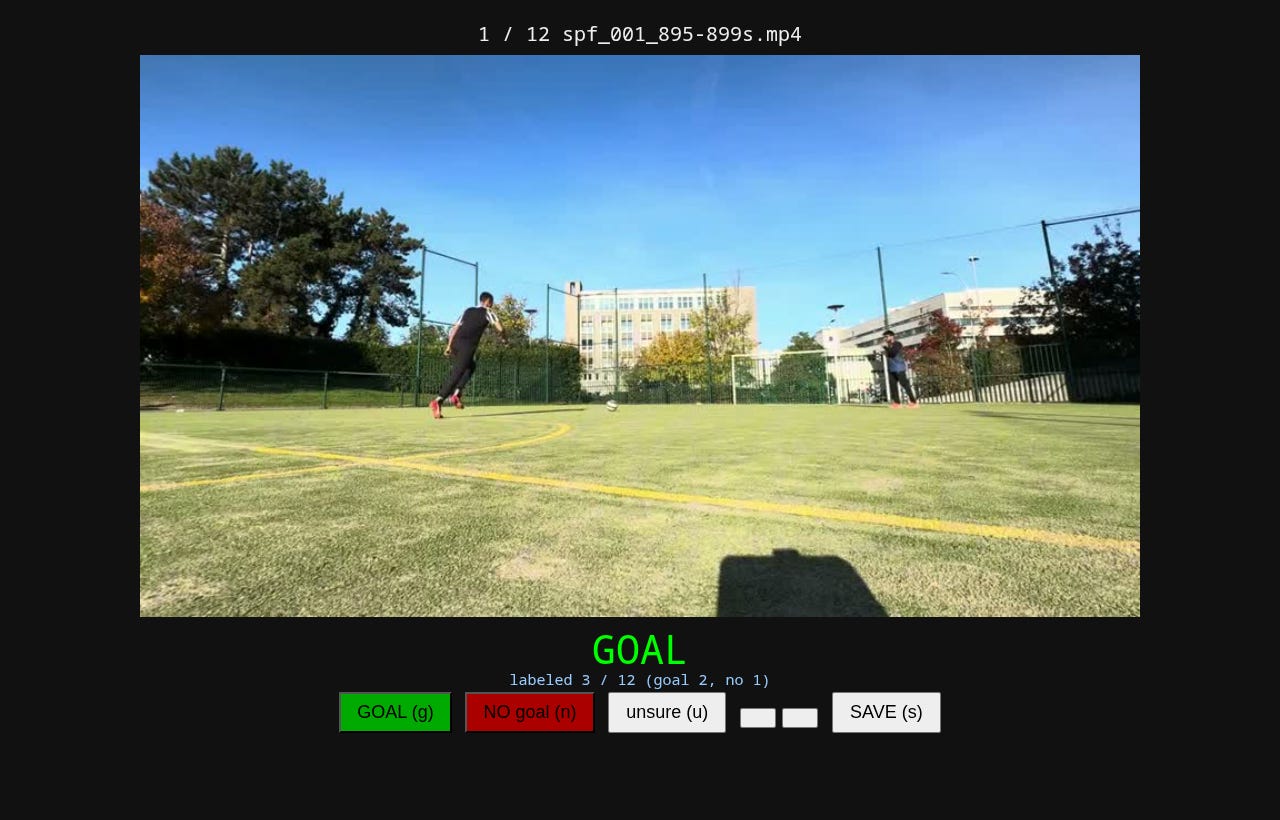
Goal annotator the ground-truth goal / no-goal / unsure labeller that every result here is scored against:
Lesson learned: my first idea (single-frame click-to-label) was useless for a fast ball I rebuilt everything to be prev/next/jump navigable with persisted state.
Auto-labelling with foundation models
The core trick for “zero hand labels” is to let foundation models be the labeller, then distil a fast model from their output.
SAM3 the workhorse, and the best single model here
SAM3 is text-promptable video segmentation. I give it "ball", "person", "goal post" and it returns tracked masks. On clean clips it is genuinely excellent crisp player and goal masks, the right ball and honestly it’s the best single model in this pipeline. When SAM3 sees the ball, everything downstream is easy.
LocateAnything the rescue for the tiny / tilted ball
When SAM3 comes up empty (the small/blurred/tilted ball from §3), I fall back to NVIDIA LocateAnything-3B, a grounding VLM that localizes an object from a text phrase. Because it reasons about the scene, it’s far more robust to scale and orientation than a pure segmenter. I run it only on the frames/clips SAM3 missed, for ball, goal and person.
Case A spf_008: SAM3 0 / 117 ball frames → LocateAnything recovered 42 / 117.

That circled blob is a ~4-pixel ball in shadow at distance. SAM3 never saw it; the VLM did.
Case B spf_067, the tilted-camera clip. SAM3 returned 0 / 108 ball frames. LocateAnything recovered the goal post 108/108 and the player 108/108 all the content was there, the camera was just rotated, and the orientation-robust VLM handled it.
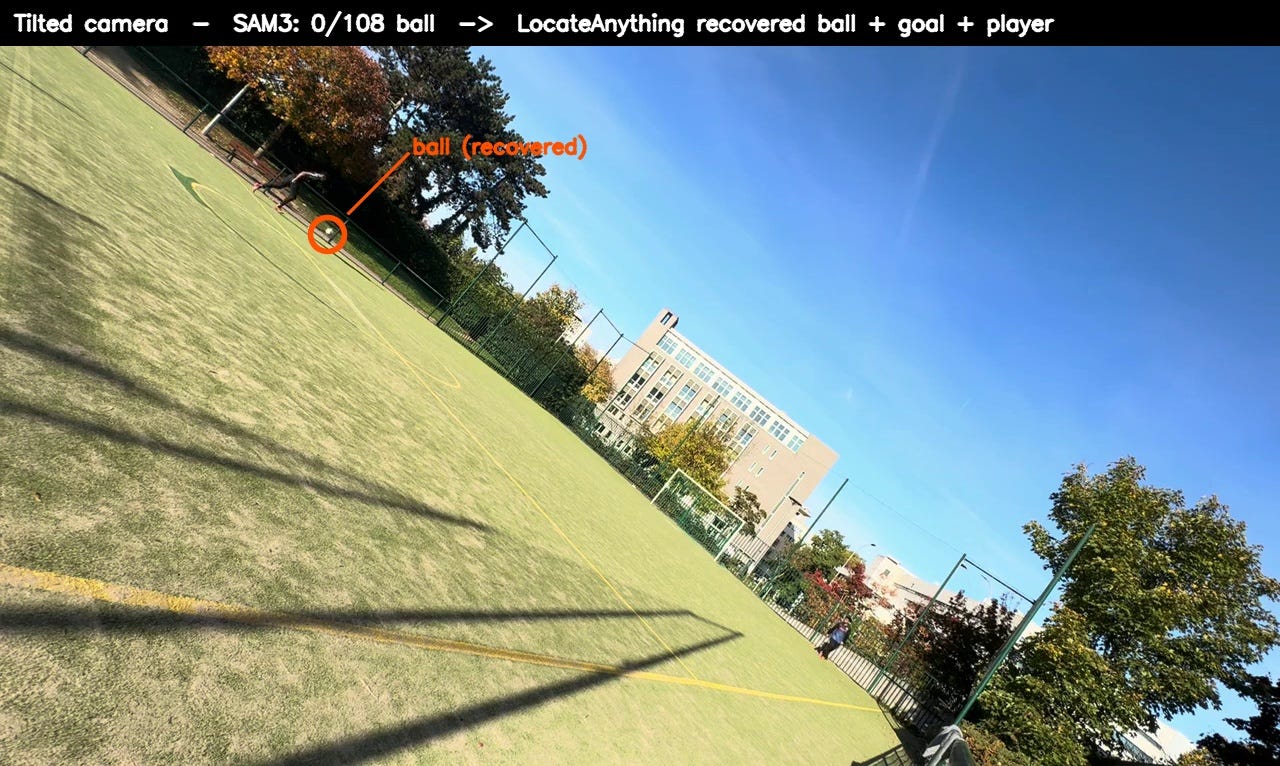
SAM3 does the bulk; LA patches the holes. Together they auto-label the entire dataset with no human boxes.
Distilling a real-time student RF-DETR-Seg
SAM3 + LA is accurate but slow (a VLM call per missed frame) you can’t ship it. So I used their combined output as a training set and distilled one fast student: RF-DETR-Seg (Roboflow, 384 px).
+--------+--------+-------------+
| split | images | annotations |
+--------+--------+-------------+
| train | 1,767 | 6,489 |
| valid | 338 | 1,233 |
| test | 636 | 2,401 |
+--------+--------+-------------+
Class design: 3 from the teacher → 5 for the student
The teacher (SAM3 + LA) only ever labels 3 classes: ball, player, goal. That’s all the foundation models know.
But possession and goal events are exactly the interactions between those things so before training the student, I derive two extra classes purely from geometry:
player_with_ball= a player whose mask intersects the ball (possession),ball_in_goal= a ball whose mask intersects the goal (a goal-contact candidate).
RF-DETR is then trained on these 5 classes (ball, player, goal, player_with_ball, ball_in_goal). The point: instead of leaving “who has the ball” and “is the ball in the goal” entirely to inference-time geometry, the detector itself learns the interaction context, which makes the player- and goal-classification more robust (e.g. it can distinguish a player on the ball from one standing away, and a ball in the net from one merely near it). The shipped real-time checkpoint uses the 3 base classes; the 5-class variant bakes the interactions into the model directly.
The student is ~50× faster, runs on ZeroGPU in the demo, and because its player masks are cleaner and gap-free MediaPipe Pose resolves on every test clip. It even recovers the ball on clips SAM3 missed, because it learned from the LA-patched labels.
Training curves
15 epochs at 384 px. Both losses are still falling and box mAP@50:95 peaks at 0.548 (epoch 11) the model is slightly undertrained, more epochs / higher resolution would still help.
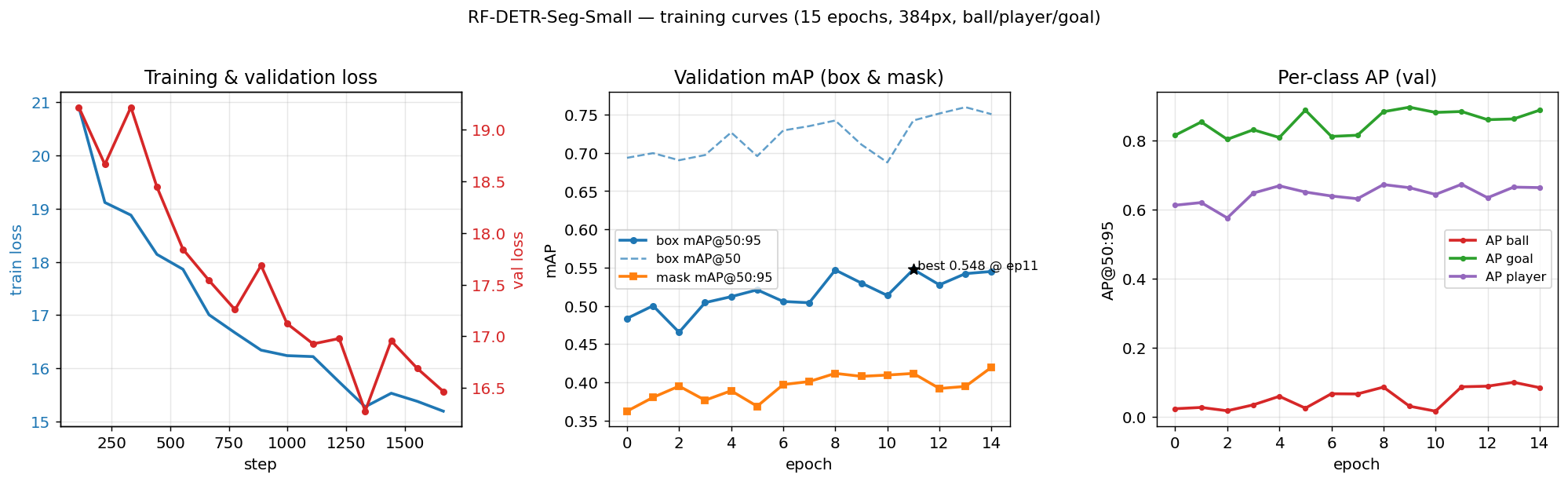
But look at the per-class panel on the right it’s the whole story of this project in one chart:
+--------+--------------+
| class | val AP@50:95 |
+--------+--------------+
| goal | ~0.89 |
| player | ~0.66 |
| ball | ~0.08 | <- the whole story
+--------+--------------+
Goal and player are easy; the ball sits near the floor. That single curve is the visual proof of §3 a 3–4 px, motion-blurred ball at 30 fps is brutal for any detector, even one trained directly on it. This is exactly why the SAM3 + LA teacher (which reasons about the scene) still beats the student on goal/leg, and why resolution is the #1 lever for the future.
Honest admission: I was lazy I distilled from SAM3 + LA instead of labelling by hand. It works, but it’s not the ceiling (see Future work).
From masks to meaning geometry & physics
The model only outputs masks. Everything a fan cares about is derived with pure geometry and physics, no extra training.

Who has the ball → who shot it:
ball ∩ playerover time gives possession; the last touch before the ball reaches the goal is the shooter. Players are drawn as masks labelledP1/P2/P3, brightening toP# BALLon possession.Pose & shooting foot: on the kick frame I crop generously around the shooter (the kicking leg swings outside the player box) and run MediaPipe Pose. The foot is whichever ankle is nearer the ball at contact.


Did it go in? (the hard part): in monocular 2D, a ball in front of the goal and a ball in the net are the same pixels. So I don’t just check “ball inside goal box” I look at the trajectory over time: a kick spike, the ball arriving at the goal (not starting there else a kickoff in front of goal reads as a goal), then rest-in-net vs rebound vs pass-over. Detection noise made the ball “teleport,” so a Hampel filter (sliding-window median/MAD) removes outliers first. Goal accuracy climbed across these fixes: 58% → 75% → 83% → 92% on the test set.
Shot speed: the ball is 22 cm, so its pixel width gives a px→metre scale;
km/h = peak_px × fps × (0.22 / ball_px_width) × 3.6, with a robust peak (92nd percentile, capped 140) so one noisy frame doesn’t report a 900 km/h rocket.
Coaching the shot a vision-LLM that sees it, two ways
Numbers and masks tell you what happened; the last step turns that into what to fix. A vision-language model looks at the strike frame(s) and grades the shot, grounded on the measured facts (goal/no-goal, foot, speed) and the biomechanics I derive from MediaPipe Pose kicking-knee bend, trunk lean, hip drive at contact, each with a “good range” and a flag.
Two design notes that mattered:
The result is already decided by the geometry/physics above, so the prompt hands the model that verdict as fact and tells it never to contradict it otherwise a small VLM will happily read “no goal” off a blurry frame. It opens by celebrating a goal or encouraging a miss, then gets specific: Verdict → Fix → Fix → Drill.
The coach is streamed separately from the analysis, so the segmentation video, pose and stats appear instantly and the written feedback fills in a moment later.
And there are two coaches behind one toggle same prompt, same grounded facts:
☁️ Online NVIDIA Nemotron-Nano-12B-v2-VL (12B). I serve the GGUF (Q4_K_M) + mmproj on a llama.cpp server on Modal (A10G GPU). The bigger model gives the richer, more polished feedback.
⚡ Offline MiniCPM-V-4.6 (OpenBMB, ~1.3B SigLIP2 + Qwen3.5-0.8B). It runs on the Space’s own ZeroGPU, no external API at all. A genuinely pocket-sized VLM that still reads the frame and coaches true to the local-first spirit of the whole project.
One is cloud-grade, one is fully on-device; you pick.
The demo UI a custom stadium on gradio.Server
The Space isn’t the default Gradio Blocks layout. It’s a bespoke football-stadium frontend (hand-written HTML/JS, an SVG top-down pitch as the background) talking to Gradio’s backend engine via gradio.Server: @app.api() exposes the analysis and coach as queued, ZeroGPU-aware endpoints, and the page is served from the same app and calls them with @gradio/client.
The details are where the fiddly hours went. Analysis and coaching are two separate calls, so the segmentation video, pose card and stats show up in a few seconds and the written feedback streams in after, the shot never waits on the language model. There’s a gallery of held-out clips so you can try it in one click without uploading anything, and a single toggle flips the coach between the online and offline models. And the small stuff that makes it feel alive: a goal fires confetti 🎉, the loader cycles football one-liners (”Counting your stepovers…”), the rendered clip is +faststart so it plays instantly, and the layout is pinned so it never breaks on resize.
It’s the same model stack, just wearing a kit instead of a form.
Results & honest evaluation
Same downstream pipeline on each detector, only the detector swapped (fair comparison).
Held-out 12-clip test set:
+-----------------------------+------+------+--------------+-------------+
| Detector | Goal | Leg | Pose-capture | Speed |
+-----------------------------+------+------+--------------+-------------+
| SAM3 + LA (teacher) | 83 % | 82 % | 92 % | ~50x slower |
| RF-DETR-Seg-Small (student) | 75 % | 75 % | 100 % | real-time |
+-----------------------------+------+------+--------------+-------------+
Per-split (goal / leg / pose-capture %):
+---------+-------+-----------+-------------------+
| split | clips | SAM3 + LA | RF-DETR-Seg-Small |
+---------+-------+-----------+-------------------+
| test | 12 | 83/82/92 | 75/75/100 |
| train | 49 | 73/71/84 | 59/53/86 |
| val | 11 | 45/88/73 | -- |
| overall | 72 | 71/75/84 | -- |
+---------+-------+-----------+-------------------+
The val goal number (45%) is low and noisy 11 clips, skewed to the hard tilted/ball-in-front cases. I report it rather than hide it. The ceiling is real: monocular goal detection tops out in the low-to-mid 80s% because of the in-front-vs-in-net depth ambiguity.
There’s something I actually like about that number, though. The big models here, SAM3, LocateAnything, the 12B Nemotron coach, are teachers, too heavy to ever sit on my footage every weekend. The thing that actually ships is small: a distilled detector that runs real-time on a free GPU and a 1.3B coach that fits on the same little Space. It’s not as sharp as a stadium of cameras, and it doesn’t need to be. It just needs to run on my phone clip, on my hardware, without sending my Saturday football to anyone’s cloud.
The pipeline, end to end
clip ──▶ SAM3 ("ball"/"person"/"goal post") ──┐
└─ 0 detections? ─▶ LocateAnything-3B ─┤ (auto-labels, zero hand annotation)
▼
RF-DETR-Seg-Small (distilled, real-time)
│ ball / player / goal masks
┌───────────────────────────────┼───────────────────────────────┐
▼ ▼ ▼
ball ∩ player ball ∩ goal + physics ball pixel width
→ who has it → shooter → goal? + timestamp → shot speed (km/h)
│
▼
MediaPipe Pose on the kick frame → shooting foot (L/R) + knee/trunk/hip angles
│
▼
goal · foot · speed · pose-angles ──▶ vision-LLM coach → Verdict · Fix · Fix · Drill
(☁️ Nemotron-Nano-12B-v2-VL on Modal · ⚡ MiniCPM-V-4.6 on the Space's ZeroGPU)
What’s next (future improvements)
I optimised for “lazy and local,” not for maximum accuracy. The obvious upgrades:
High-quality manual annotation. Distilling from SAM3 + LA is convenient but it’s a ceiling-limiter a few hours of careful hand labels would lift goal/ball accuracy significantly. This is the single biggest lever.
Bigger backbone & higher resolution. Move from RF-DETR-Seg-Small to a Large model at higher input resolution directly attacks the tiny-ball problem.
Homography → top-down pitch map. Estimate the pitch plane and project players/ball onto a 2D map. That adds spatial robustness, makes “in front of vs in the net” tractable, and unlocks proper positional analytics.
More sessions / players to generalise beyond one pitch and two players.
Why I built this (and why local)
I’m a big football fan, and I record my football journey on YouTube. I’d earlier built a Euro football-outcome prediction project (part of my 100-days-of-code) and was awarded by FIFA for its unique method so blending football and AI is a bit of a personal tradition.
Now it’s World Cup 2026, the whole world is watching football, and I finally wanted to build the thing I’d always wanted: a personal football AI on my own footage. I had the content (years of recordings, including the shooting sessions with Adam) and, thanks to Roboflow and SkalskiP, the ideas player/jump detection, ball physics, RF-DETR, SAM to actually pull it off.
And the part I care about most: I’m a big fan of local models and owning them locally. Everything here runs on open models I control SAM3, LocateAnything, RF-DETR, MediaPipe, MiniCPM-V, Nemotron no proprietary API in the loop. The offline coach runs on the Space’s own GPU; even the “online” one is an open NVIDIA model I self-host on Modal, not a closed endpoint. The Build-Small Hackathon was the perfect excuse to finally sit down and build it.
I still drop my own session clips into it now that it’s working, which is the real test for me: the BBC’s 3D experience lights up when a World Cup match is on TV, mine lights up when Adam and I finish shooting on a Saturday. Same idea, my pitch.
Links
🎬 Live demo https://huggingface.co/spaces/build-small-hackathon/kicky-ai
🤖 Model https://huggingface.co/build-small-hackathon/kicky-ai-rfdetr-seg
📦 Dataset https://huggingface.co/datasets/build-small-hackathon/kicky-ai-spf
📺 YouTube @dcrey7 (if this was useful, a subscribe means a lot 🙏)
Stack: SAM3 · NVIDIA LocateAnything-3B · RF-DETR-Seg (Roboflow) · MediaPipe Pose · NVIDIA Nemotron-Nano-12B-v2-VL (llama.cpp on Modal) · MiniCPM-V-4.6 (OpenBMB, on-Space ZeroGPU) · OpenAI Codex (annotation tools) · gradio.Server · OpenCV.